최근 RabbitMQ를 사용할 일이 있었다.
이해가 부족해서 중간에 잘못된 코드를 사용해서 문제가 발생했다.
이번 기회에 RabbitMQ란 무엇인지, 왜 쓰는지, 어디에 쓰는지 학습해보고 간략하게 정리해보고자 한다.

메세지 드리븐?
서비스 사이에 비동기적으로 메세지를 전달하는 방식이다.
그래서 서비스들은 느슨한 결합 -> decoupling 된 의존성을 가지게 된다. -> 부하 관리, 탄력적인 흐름 제어가 가능함
이 메세지 드리븐의 장점을 얻기 위해 메세지 미들웨어를 쓸 수 있다. -> 그래서 MQ를 쓸 수 있다.
그런데 카프카는?
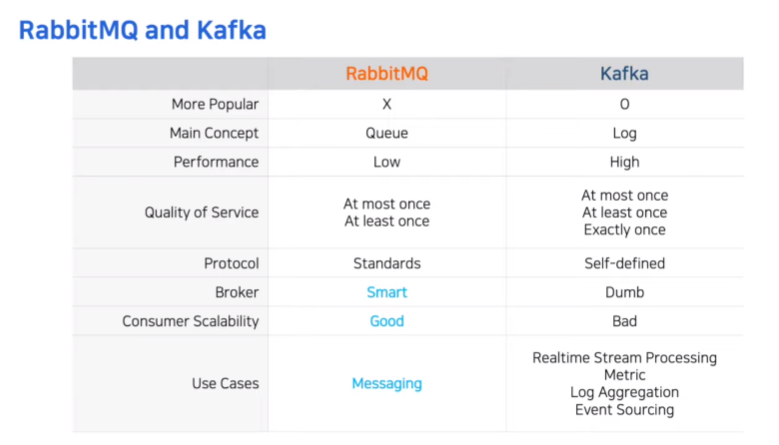
RabbitMQ는 큐
카프카는 로그
큐
- 선입 선출
- 메세지는 소비되면 큐에서 삭제됨
- 일시적인 메세지 보관
- 생산자, 소비자가 독립적 비동기적으로 존재할 수 있다.
- 큐잉, 버퍼 역할
- RabbitMQ는 이 역할을 그대로 수행함
로그
- 파일에 쓰는 것과 같다.
- 메세지를 영구적, 긴 기간 동안 보관함
- 같은 메세지를 반복적으로 읽을 수 있음
- 이벤트 소싱을 구현할 떄 매우 좋은 미들웨어임.
- Append
- Loong term
- Replay
- 소비자가 어떤 메세지를 읽었는지 관리하지 않음
- 동작이 매우 간단함
RabbitMQ
- 스마트 브로커 <->덤브 컨슈머
단점이 하나 있다. 카프카와 비교해 느리다. 경우에 따라 성능이 중요한 서비스에서는 치명적일 수 있다.
하지만 대부분의 경우 스케일업과 아웃으로 충분히 성능 확보가 가능하긴 함
loose coupling -> 대신 느림
카프카
- 덤브 브로커 <-> 스마트 컨슈머
단순히 메세지를 덧붙인다. 브로커는 컨슈머가 메세지를 어디까지 읽었는지 관리하지 않음.
그래서 메세지를 어디까지 읽었는지는 컨슈머에서 직접 관리해야한다.
그래서 어플 개발 시 개발 리소스가 RabbitMQ에 비해 많이 들어간다.
고려해야할 점들도 많아진다. 개발자 실수에 의해 의도치 않은 실수 가능성이 스마트 브로커보다 큼
tight coupling -> 대신 빠름
사용성
RabbitMQ가 좀 더 사용성이 좋음
- 가볍다.
- 설치 운영이 쉬움
- 빌트인 매니지먼트 콘솔이 있음
카프카는 좀 구성이 복잡함
zookeeper 설정 필요함
특징
RabbitMQ
- 전통적인 메세지 브로커
- 동적으로 안전하게 큐 생성, 삭제,
- 메세지 라우팅 등 메세지 기능에 특화되어 있음
카프카
- 실시간 프로세싱
- 메트릭
- 이벤트 소싱
- 다양한 곳에서 사용 가능함
RabbitMQ도 위처럼 사용하거나 그 역도 가능함
하지만 좀 더 쓰임새에 맞게 미들웨어를 골라서 사용하는게 올바름
multi-tenancy?
- 여러 사용하자가 같은 리소스를 공유함
- 그래서 저렴함
- 특정 유저가 순간적으로 모든 자원 점유 가능 -> Noisy Neighbor Effect
RabbitMQ Mandatory ?
RabbitMQ TTL ?
- 새로운 메세지가 들어오면 TTL이 갱신된다고함
- 메세지가 큐에 남아있을때 큐가 삭제되면 메세지를 자동으로 이동시켜주는 dead-letter-exchange라는 기능이 있다고 함
RabbitMQ 설정
네트워크 파티션이 발생할때?
- 노드가 통신이 끊겨 클러스터가 깨지거나 특정 노드가 클러스터에서 제외되는 상황이다.
- RabbitMQ의 VM 하이버바이저 장애로 발생 가능함
래빗 클러스터가 어떻게 대응할지 설정 가능함
pause-minority ?
- 서로 통신안되는 노드 중 마이너한 쪽이 멈추는 설정임
ignore? (기본 설정임)
- 네트워크 파티션이 발생해도 각 노드들이 계속 서비스하는 설정이다.
- 만약 복제된 큐가 서로 통신이 끊어진 노드에 있다면 노드간 큐가 동기화 되지 않기 때문에 메세지가
- 중복적으로 소비될 수 있다.
- 그래서 QOS를 At most once로 선택했다면 ignore를 사용하면 안된다.
queue_master_locator
- client-local이 기본 설정임
- 생산자, 소비자가 접속한 노드에 큐를 할당하는 것이다.
- 기본 설정을 사용하면 특정 노드에만 큐가 생성될 수 있어서 래빗 클러스터에 불균형을 초래해서 전체 성능에 부정적인 영향을 미칠 수 있다.
min-masters
- 즉 큐가 적게 할당된 노드에 새로운 큐가 만들어지게 할 수 있다.
- 래빗은 큐를 다시 밸런싱하는 명령어도 제공함
- 부하를 많이 발생하는 명령어라 트래픽없는 시간대 골라서 실행하는 게 좋음
큐 고가용성 설정
- 추가 지정설정임
- 세 개 노드에 큐를 복제하고 노드가 네트워크 파티션에서 복구되서 다시 클러스터에 합류하면 자동 큐 동기화를 하도록 설정한다.
- 네트워크 파티션, VM 하이퍼바이저 장애는 거의 발생하지 않지만 발생했을때 이런 설정이 자동으로 되어있으면
- 서비스 복구 시간을 굉장히 줄일 수 있음
메모리 설정
큐 사용 메모리 설정
high_watermark_relative = 0.4 VM전체 메모리 40퍼센트까지 쓸 수 있다는 뜻
넘어가면 래빗은 더 이상 발행하지 않는다. -> 즉 생산자는 더이상 메세지를 발행할 수 없다.
-> 메모리 줄이려면 메세지를 소비해야한다.
high-watermark_pagin_ratio -> 메모리 데이터를 디스크로 내리는 설정임
0.75? 큐 사용 메모리 75퍼센트 이상 사용될 경우 메모리 데이터를 디스크로 내리는 기능이다.
메모리 데이터를 디스크로 내리면 부하가 래빗 클러스터 성능에 영향을 준다.
디스크에 내리는 속도보다 메모리에 쌓이는 속도가 더 빠르면 여전히 메세지 발행이 제한될 수 있다.
메모리 설정은 보수적으로 설정하는 게 좋다고 함
RabbitMQ 성능
https://chopstick-91.tistory.com/160
'Backend > RabbitMQ' 카테고리의 다른 글
| [RabbitMQ] RabbitMQ 구성요소와 용어 정리 (0) | 2023.10.28 |
|---|---|
| [RabbitMQ] RabbitMQ 공부 자료 모음 (0) | 2023.10.28 |
| [RabbitMQ] 알아두면 좋은 추가 개념들 (0) | 2023.10.28 |
| [RabbitMQ] vhost에 대한 이해 (0) | 2023.10.28 |
| [RabbitMQ] RabbitMQ vs Kafka 성능 비교 논문 (0) | 2023.10.27 |