최근 Amazon DynamoDB를 사용할 일이 많다.
DynamoDB는 간단하다는 점이 좋았다.
그럼에도 잘 알고 사용해보고자 DynamoDB에 대한 간략한 내용을 정리해보고자 한다.
DynamoDB란?
AWS에서 제공하는 서버리스 기반 key value 기반 NoSQL데이터베이스다.
높은 성능과 비용적 이점이 있다고 한다.
특징
- NoSQL 데이터베이스
- NoSQL데이터베이스에는 JOIN이 없다.
- JOIN개념이 없기 때문에 정규화도 불가능하다. 그래서 NoSQL에서는 반정규화를 한다고 한다.
반정규화란?
데이터베이스의 성능 향상을 위해서 데이터 중복을 허용하고 조인을 줄이는 데이터베이스 성능 향상 방법이다.
반정규화는 조회(select) 속도를 향상시키지만 데이터 모델의 유연성은 낮아진다.
반정규화를 적용하면 데이터 무결성이 깨질 수 있는 위험이 있다.
데이터를 조회할 때 조인으로 인한 성능 저하가 예상될 때 성능이 저하될 것이 예상되는 경우 수행한다.
- RDBMS는 종류나 특성에 따라 테이블을 나누지만 DynamoDB에서는 모든 것이 하나의 테이블에 표현 가능하다.
- DynamoDB는 HTTP로 통신한다.
- 다른 DB리소스들은 TCP Connection 기반인데 DynmoDB는 Connectionless하다고 한다.
- 서버리스 기반이다.
- 서버리스라서 DynamoDB를 위한 별도의 서버가 존재하지 않는다. 그래서 요청한 만큼만 비용을 지불한다.
- AWS Lambda 같은 서버리스 기반 서비스와 같이 사용하면 좋다.
- Key-value 데이터베이스다.
- Key를 제외한 테이블 속성을 미리 정의해둘 필요가 없다.
- 데이터에 대해 미리 스키마가 만들어져있어야 하는 RDBMS와는 달리 DynamoDB는 유연하게 데이터를 처리할 수 있다.
- DynamoDB는 NoSQL이기 때문에 RDBMS와 같이 테이블이 데이터베이스에 종속되어있지 않다.
- SSD 스토리지를 사용하기 때문에 읽고 쓰는 속도가 빠르다.
- 모바일, 웹, IoT 데이터 사용 시 추천된다.
- 테이블 생성 시 스키마 생성이 필요 없어서 실시간으로 들어오는 데이터를 보관하는 데 탁월하다.
- Auto-Scailing 기능이 있다.
- DynamoDB 데이터는 AWS IAM으로 관리 가능
- 특정 테이블, 특정 데이터만 접근 제한하는 특별 IAM 역할도 가능하다.
DynamoDB 파티셔닝 원리

- DynamoDB 내에는 해쉬 함수 존재
- 파티션 키는 해쉬 함수를 거쳐서 데이터를 저장할 파티션을 결정
- 동일한 파티션 키를 지닌 데이터는 물리적으로 가까운 위치에 저장된다. 이때 데이터를 구분하기 위해 정렬 키 사용한다.
- 정렬 키를 사용하면 동일한 파티션에 저장된 데이터는 정렬 키를 기준으로 저장된다.
Key
파티션 키 (Partition key = PK = Hash Key)
- 물리적인 공간인 파티션을 구분하기 위한 키
- 스케일이 아무리 커져도 주소를 알고 있어서 데이터를 빠르게 가져올 수 있다.
- 파티션 키로는 일치하는 값만 가져올 수 있고, =, >, < 등의 범위지정 방식 검색은 지원하지 않는다.
정렬 키 (Sort key = SK = Range Key)
- 파티션 안에서 데이터를 정렬하기 위한 키
- DynamoDB에서는 Number, Binary, String 타입을 지원 (String은 utf-8)
- 단순 정렬이기 때문에 파티션 사이즈가 커져도 데이터를 빠르게 가져올 수 있다.
- 파티션 키와 달리 범위지정 방식 검색 지원한다. 하지만 정렬 키만 가지고는 검색할 수 없다.
Primary Key (PK)
(primary key를 표현할때는 PK라고 하지 않고 그냥 primary key라고 한다.
partition key일 경우만 PK라고 부르는 경우가 많다.)
PK를 사용해서 데이터 쿼리
Partition Key
- 데이터 나누고 분리시키는 키
- Unique Attribute
- 실제 데이터 들어가는 위치 결정
- Partition Key 사용 시 동일한 두 개 데이터가 같은 위치에 저장될 수 없음
- Partition Key 중복 불가
Composite Key
- Partition Key + Sort Key
Index
- 특정 컬럼 만을 사용해서 쿼리
- 테이블 전체가 아닌 기준점(Pivot)을 사용해서 쿼리 이뤄짐
- 매우 큰 쿼리 성능 효과
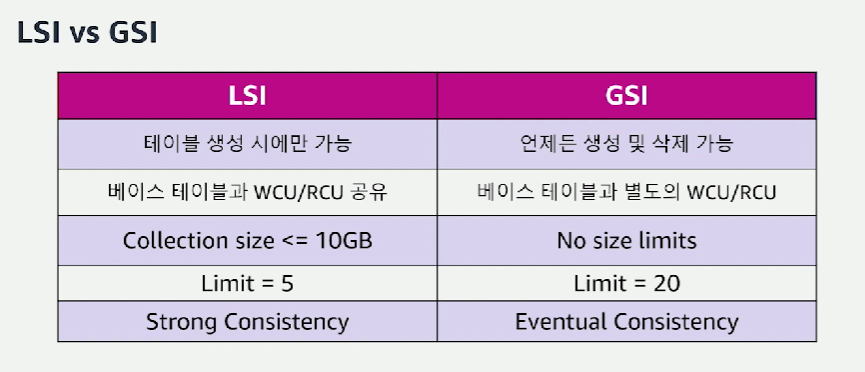
로컬 보조 인덱스 (LSI)
- 파티션 키 및 정렬키를 합친 복합 인덱스
- 동일한 파티션 키 내에서 정보들을 분리하고 싶을 때 사용함
- 로컬 인덱스는 테이블을 만들 때 미리 설정해둬야함
글로벌 보조 인덱스 (GSI)
- 기본키(파티션 키)나 정렬키와는 별개로 특정 키를 인덱스 키로 활용
- 콘솔에서 해당 테이블 클릭해서 인덱스를 만들 수 있음
- 기존 attribute 중 하나를 선택해서 자유롭게 추가, 수정, 삭제할 수 있음
파티션 키 외 내용으로 쿼리해야하는 경우가 있을 때 이 보조 인덱스(LSI, GSI)의 개념이 중요해진다고 한다.
SQL에서는 Foreign key와 Join table로 해결하지만 NoSQL에서는 인덱스라는 보조키로 해결한다.
보조 인덱스
SQL의 인덱스와 비슷한 역할
모든 보조 인덱스는 정확하게 하나의 테이블과 연결되어 데이터를 얻음
왜 로컬 인덱스를 사용할까?
로컬 인덱스를 사용하는 경우는 hot key 이슈를 막기 위해서다.
hot key 이슈는 특정 파티션 키만 유독 많이 사용되서 용량이 몰리는 것을 의미한다.
Query vs Scan
DynamoDB 데이터 읽어오는 2 가지 방식
Query
- Primary Key를 사용해서 데이터 검색
- Query 사용 시 모든 데이터 반환
Scan
- 모든 데이터를 불러옴 (Primary Key 사용 X)
- 순차적 방법
- 테이블 크기가 작을 때 사용
결론
- Query가 Scan보다 더 좋음
DynamoDB 용량 모드
DYnamoDB는 온디맨드와 프로비저닝 방식의 두 가지 용량 모드가 있다.
온디맨드 (On-demand)
- 사용한 가격 만큼만 가격을 지불
- 많은 트래픽이 발생할 수록 이전에 도달한 최대 트래픽 수준까지 확장
- 이전 도달 최대 트래픽을 넘는다면 이전 2배에 해당하는 크기로 자동 조정
프로비저닝 (Provisioned)
- 프로비저닝 방식은 애플리케이션에 필요한 초당 읽기 및 쓰기 회수를 지정
- 오토 스케일링을 사용해서 트래픽 변경에 따라 프로비저닝된 용량을 자동으로 조정
- 프로비저닝 모드를 사용하면 비용을 예측하는 데 많은 도움이 됨
DynamoDB Stream
- DynamoDB 테이블에서 일어나는 일들 (삽입, 수정, 삭제 등 이벤트들)이 일어날 시 시간적 순서에 맞게 Streams에 기록
- Log는 즉각 암호화가 일어나고 24시간 동안 보관
- 주로 이벤트를 기록하고 이벤트 발생을 외부로 알리는 용도로 사용함
- 이벤트 전 후 에 대한 상황 보관
DynamoDB를 사용하면 저렴한 가격으로 높은 성능의 데이터베이스를 사용할 수 있다.
분산 스토리지 시스템 Dynamo의 기원
아마존은 지구 규모 스케일 서비스를 운영하면서 자신의 요구와 가장 잘 맞는 범용적인 분산 스토리지 시스템을 만들었다.
그게 Dynamo다.
이 시스템을 만들고 운영한 경험을 논문으로 발표했고 이 논문이 분산 스토리지 시스템 생태계에 큰 영향을 주었다.
그래서 이 논문의 영향으로 오픈소스 Cassandra가 개발되고 AWS에서는 SimpleDB와 DynamoDB가 개발되었다.
Dynamo는 DynamoDB와 같은 것이 아니다. DynamoDB의 뿌리가 되는 시스템이 Dynamo인 것이다.
아마존은 Oracle이 제공하는 엔터프라이즈 데이터베이스 스케일을 넘어서 지구 단위 글로벌 서비스로 성장함
때문에 직접 DB를 설계하고 관리하기로 결정함
아마존은 다음 특징을 가진 데이터베이스를 고민하게 된다.
- 간단한 쿼리 모델
- 느슨한 ACID
- 효율성
Dynamo는 네트워크 장애가 무조건 발생한다는 가정 아래 가용성을 최대로 높이도록 디자인되었다.
Dynamo는 "항상 쓰기 가능한" 데이터베이스를 목표로 한다.
Dynamo는 결과적 일관성(Eventual Consistency) 특성을 갖게 된다. 일시적으로 데이터가 일관적이지 않을 수 있지만 결국 같은 데이터를 보장한다는 뜻이다.
참고로 DynamoDB와 Dynamo는 확실히 구분되는 개념이다. Dynamo는 DynamoDB의 기원이 되는 분산 스토리지 시스템을 의미한다.
강력한 읽기 일관성이 필요한 경우에는 DynamoDB가 그다지 좋은 선택지가 아닐 수 있다.
일관성이 중요한 애플리케이션은 RDB를 사용하는 것이 일반적으로 더 좋을 수 있다.
아이템 컬렉션 = PK가 같은 아이템의 모음
Amazon DynamoDB 키 디자인 패턴
https://www.youtube.com/watch?v=I7zcRxHbo98
PK 덕분에 동일한 시간에 아이템 검색이 가능하다.
Partition Key
- Key-Value 액세스 패턴
- 필수 사용
Sort Key
- 1:N 관계 모델링
- PK + SK = primary key
- DynamoDB에서는 primary key로만 데이터 검색이 가능하다. 이게 없으면 조회가 안된다.
- RDBMS는 스케일 업을 선택할 수 밖에 없다.
- 하지만 NoSQL은 처음부터 대규모 트래픽을 염두에 두었기 때문에 많은 샤드로 스케일 아웃이 가능하다.
- 그렇다면 수평으로 무한대에 가깝게 확장 가능한 데이터를 어떻게 설계할까?
- NoSQL은 성능이 작은 머신을 스케일 아웃하는 방식이다. 그래서 트래픽이 특정 머신에 몰리면 안된다.
- 파티션 단위는 초당 1000개 쓰기, 3000개 읽기 ,10GB저장의 제약 조건이 있다.
- 파티션 개수가 늘어난다는 것은 해당 테이블의 처리량이 늘어난다는 개념이다.
- 여러 개 파티션이 골고루 사용되도록 키 디자인하는 게 중요하다.
- 데이터는 항상 3개의 가용 영역에 복제된다.
- 서비스는 3개의 가용 영역에서 실행된다.
- 아이템 최대 크기는 400KB이다.
- 하지만 400 KB 모두 사용하는 것은 권장되지 않는다. 차라리 아이템을 많이 가져가는 게 오히려 낫다.
- 스케일링은 파티셔닝을 통해서 이루어진다.
- DynamoDB에서는 1MB 단위로 Scan을 한다.
- 가능하다면 벌크 작업을 하기 보다는 나눠서 작업을 하는 게 DynamoDB에 좋다.
- ACID가 지원되는 트랜잭션도 존재한다.
- GSI (Global Secondary Index)은 서비스 오픈 후 대응해나갈 수 있는 방법이다.
- LSI (Local Secondary Index)은 쿼리 유연성이 떨어져서 별로 사용 권장되지 않는다.
DynamoDB 데이터 모넬링 TENET

- DynamoDB는 무한대에 가까운 아이템 개수 중 하나 혹은 몇 개 아이템을 primary key로 빠르게 찾는 걸 잘한다.
- 대량의 집계, full scan등은 잘 못한다.
- RDBMS처럼 엔티티별로 설계하는 게 아니라 하나의 테이블 별로 설계해야 한다.
- DynamoDB에서는 하나의 큰 테이블을 설계하는 것이 이점이 더 좋다.
- 애플리케이션 종류는 OLTP일 경우 사용해야 한다. OLAP는 분석 파이프라인을 만들어서 다른 곳에서 해야 한다.
- 백업 정책은 반드시 고민해야 한다. 복원할 수 없는 백업은 의미가 없다.
- primary key로만 데이터를 조회할 수 있어서 중요하다. 어떻게 읽고 쓰는 가를 잘 고려해서 primary key를 식별해야 한다.
- RDBMS는 공식이 있어서 다들 비슷하게 만들어낸다. 하지만 NoSQL의 키 디자인은 10명이 하면 10개의 디자인이 나온다.
디자인 패턴 및 비정규화
DynamoDB가 잘하는 건 무한하게 많은 아이템 중에 하나 혹은 몇개를 일정한 시간에 찾아내는 것이다.
RDBMS
- 데이터 액세스 패턴을 고민하기보다는 데이터 모델 정규화하는 데 노력한다.
- Ad-hoc 쿼리가 가능하다.
- RDBMS의 시기는 CPU보다 디스크가 비쌌다. 그래서 정규화로 데이터 중복을 줄여서 최소를 디스크에 저장하려 한 개념이다. 하지만 2000년대 중반 디스크가 싸지면서 key value가 부상했다. 오히려 디스크를 많이 쓰고 런타임의 CPU를 줄이고자 한거다.
DynamoDB는 애플리케이션이 사용하는 모든 데이터 액세스 패턴을 알고 시작해야 한다.
JOIN이 안되기 때문에 Pre-computation이 필요하다.
DynamoDB에서는 #을 사용해서 복합 키를 사용한다.
SK
- IoT 시간별 유입 로그
- 소셜 네트워크의 포스트 리스트
- 이커머스 주문 상세정보 혹은 구매 이력
싱글 테이블 디자인
모든 엔티티를 하나의 테이블로 설계하는 방법
장점
- 적은 운영 부담
- 높은 테이블 최대 성능 및 쓰로틀링 경감
단점
- 높은 러닝 커브
- 예외 케이스: 시계열, 다른 액세스 패턴의 엔티티
안티패턴
PK를 userId로 고정하고 시작하는 습관
- 일반 사용자와 VIP를 같은 키 디자인으로 해결하려는 습관
- 대량 트래픽을 유발하는 heavy user를 항상 고민해야함
엔티티 별로 테이블을 만들려는 습관
- 테이블 개수가 많아지면 좋지 않다. 손이 많이 간다.
GSI를 많이 사용하려는 습관
- 즉시 눈에 보이는 비용이기에 사용을 최소화해야 한다.
명심해야할 것은 우리가 DynamoDB를 쓰기로 했다는 것은 RDBMS의 스케일로는 어려운 대규모 서비스를 타켓팅하고
글로벌로 언제든 나갈 수 있는 탄력있는 데이터베이스 레이어를 쓰고자 하기 위함이다.
키 디자인 풀 사이클
- 비즈니스 유즈 케이스 이해하기
- ER 다이어그램 그리기
- 이건 RDBMS의 작업이라는 생각을 할 수 있다. NoSQL이어도 1:N, N:N등을 정하면 키 디자인 패턴이 달라진다. 자세히 그리기 보다는 단순히 엔티티 간의 관계만 표현할 수 있는 정도면 된다.
- 모든 데이터 액세스 패턴 정리하기
- 키 디자인 시작하기
대부분의 스타트업들이 초기에는 RDBMS로 시작했다가 이후에 샤딩이냐 NoSQL사용이냐의 기로에 선다.
액세스 패턴
- get customer for a given customerid
- get product for a given productid
- get all order details for a given orderid
이런 식으로 액세스 패턴을 정의한다. 실제 현업이라면 read, write 별로 디테일하게 구분해서 정리해야 한다.
DynamoDB는 키 디자인만 잘해도 운영 부담이 거의 없다.
DynamoDB로 구현해보는 게임 데이터베이스
https://www.youtube.com/watch?v=1nE609C6-SI
단일 테이블 + "추상적"인 Primary Key를 가져가는 게 좋다.
partion Key자체를 PK, sort key 자체를 SK라고 정의한다.
지금 GSI1PK에도 나중에 organizations가 아니라 다른 걸 쓰고 싶다면 그때 가서 바꿀 수도 있는 개념이다.

사전에 조인된 형태로 만드는 것도 하나의 방법이다.
굉장히 유연한 설계로 가능성을 열어놓았다는 것이 핵심이다.
내 워크로드 특성에 따른 Amazon DynamoDB 비용 최적화하기
https://www.youtube.com/watch?v=c58SsQ70QQ8
핵심 청구 내역
- 컴퓨팅: WCU/RCU
- 스토리지
- 데이터 전송
일반적으로는 컴퓨팅과 스토리지 비용이 데이터 전송에 비해 압도적이기 때문에 이에 집중하는 것이 좋다.
DynamoDB에서는 싱글 테이블 디자인을 항상 고려하라.
DynamoDB에서는 키 디자인이 가장 중요하다.
파티션의 개수는 늘어나거나 유지된다.
그래서 갑자기 스파이크 치는 상황이면 온디맨드 모드가 더 좋다.
프로비저닝 모드
- 꾸준한 워크로드
- sign 그래프의 트래픽
- 트래픽 규모를 예측할 수 있는 이벤트
- 지속적인 모니터링 필요
온디맨드 모드
- 트래픽 예측이 불확실한 워크로드
- 자주 유휴 상태인 워크로드
- 트래픽이 알려지지 않은 이벤트
- "설정하고 잊어버리세요"
데이터의 증가 속도는 생각보다 아주 빠르다.
데이터 관련성은 시간이 지남에 따라 감소한다.
오래된 데이터는 덜 자주 액세스된다.
시간이 지남에 따라 스토리지 비용이 증가해서 컴퓨팅(WCU/RCU)비용을 초과한다.
이걸 어떻게 해결할까?
오래된 데이터 삭제?
- 보유 데이터 양을 제한
- 고객 경험에 영향을 미침 (고객이 싫어할 수도 있음)
- 중요한 인사이트를 잃어버림 (데이터를 삭제?)
데이터 분할?
- 핫 데이터와 콜드 데이터를 분할한다. 서로 나눠서 다른 스토리지를 사용한다.
- 콜드 데이터 조회 시 핫데이터보다 더 많은 지연시간이 걸릴 수 있다.
- 데이터 이동을 위한 맞춤형 솔루션 구축 및 관리
- 서로 다른 API를 사용해서 두 서비스 지점의 데이터에 액세스
위 문제 해결을 위해 DynamoDb Standard-IA가 등장했다.
- 데이터에 자주 액세스하고 컴퓨팅이 주요 비용인 경우 - Standard 테이블 클래스
- 데이터에 자주 액세스하지 않고 스토리지가 주요 비용인 경우 - Standard-IA 테이블 클래스
비용은 클라우드에서 가장 중요하다.
비용 줄이기
fullName => fn
email => e
userId => uid
위 처럼 줄여서 사용한다.
관계형 DB는 create table로 테이블 스키마를 지정하면 동일한 테이블의 모든 아이템 혹은 로우는 동일한 스키마를 갖는 것이 전제라서 실제 디스크에는 attribute네임은 제외하고 값만 저장된다.
하지만 NoSQL은 스키마리스해서 모든 아이템의 스키마가 다를 수 있기에 스토리지에 저장할때
attribute이름과 값을 함께 저장한다. 그러니 줄여서 저장하는 게 좋을 수 있다.
변경이 잦은 데이터와 그렇지 않은 데이터는 분리
자주 사용되지 않는 쿼리에 대한 인덱스를 만들지 않는다.
DynamoDB TTL은 글로벌 테이블에서는 신중하게 사용
즉시 값이 보여야하는 읽기 api가 아니라면 eventually consistent read를 통해 비용을 절감하자.
1년 또는 3년 단위로 구매하자.
용량모드
프로비저닝 - 사용 여부와 관계 없이 매 시간 당 지불 방식
온디맨드 - 요청 당 지불 방식
DynamoDB 키 디자인
이 부분은 특별하다할 내용이 없다.
DynamoDB에서는 가능하다면 Single Table design을 가져가는 것이 가장 좋다.
https://changhoi.kim/posts/database/dynamodb-single-table-design/
SQL vs NoSQL
- SQL은 너무 복잡하고 스키마도 있는 상황에서 아무렇게나 저장할 수 있는 방법에 대한 고민으로 나온 게 NoSQL이다.
- NoSQL은 Json파일을 빠르게 저장할 수 있는 시스템이라고 보면 된다.
- SQL은 테이블 만들고 컬럼별로 넣는 방식이다.
- NoSQL은 그냥 Json을 쉽게 넣을 수 있는 개념이다.
- SQL은 구조가 잘 잡혀있고 search가 빠르다. 제약없이 이상한 데이터가 들어올 수 없다.
- NoSQL은 SQL이 복잡했다는 의견 하에 SQL의 많은 Nomalization 등 제약이 많다는 개념 하에 등장했다.
- NoSQL는 Consistency 보장이 일반 SQL과 좀 다르다.
- SQL에서는 write 중에 lock을 거는게 DB 수준에서 보장이 된다.
- 동접이 엄청 크다면 DB하나로 버틸 수가 없다. DB는 write에서 Lock이 걸리기 때문이다. 이걸 해결하려고 다양한 시도가 있었고 이를 위해 write는 master, read는 replica에서 하는 방식도 있었다. 그런데 NoSQL로 오면서 애초에 시대가 많이 바뀌기도 했다.
- 분산 DB를 지원하는 NoSQL이 굉장히 많다.
- NoSQL은 클라우드에서 돌릴 때 꽤 금액이 나온다.
- NoSQL은 유연하다.
- SQL진영에서 NoSQL의 유연성을 일부 차용할 가능성이 있다.
DB throttling이란?
Database throttling refers to the process of limiting or controlling the rate at which requests or operations are executed on a database system. This technique is often used to manage resource usage, maintain performance, and prevent system overload.
Throttling can be applied to various aspects of database interactions, such as:
Read/Write operations: Limiting the number of read and write operations per unit of time to prevent the database from being overwhelmed with too many requests, ensuring smooth operation.
Connections: Restricting the number of concurrent connections to the database, which helps manage resources more effectively and prevent the system from being overwhelmed by a large number of connections.
Query execution time: Setting a limit on the time a query can run to avoid long-running queries that can negatively impact overall database performance.
Database throttling can be enforced through various methods, such as using built-in features in database management systems, implementing custom middleware, or using third-party solutions. It is an essential aspect of managing and scaling database systems to ensure they can handle increasing loads and maintain optimal performance.
정규화란?
개인적은 생각을 말해보고자 한다.
최근 DynamoDB를 사용할 일이 많았다. 굉장히 직관적인 개념과 간단한 사용법에서 매력을 느꼈다.
key value 형식의 NoSQL이라 그런지 Redis처럼 간단하게 사용할 수 있었다.
한 가지 흥미로웠던 점은 이런 DB의 등장이 시대상과 연결된다는 점이다. RDBMS가 등장했을 당시 CPU보다 Disk가 비쌌기 때문에 Disk에 들어가는 정보를 최소화시키고 대신 런타임의 CPU에게 일감을 몰아줬지만 이제 Disk가 기하급수적으로 저렴해진 시대기 때문에 Disk에 들어가는 정보를 최소화시키기보다는 오히려 런타임 CPU의 부담을 줄여준다는 패러다임은 기술을 바라보는 새로운 시각을 주었다.
시대상과 기술이 연결된다는 개념을 처음으로 확인했다.
흥미로운 DB고 NoSQL은 어쩌면 당연한 흐름이라는 생각이 들었다.
물론 상황에 따라서 RDBMS를 사용하거나 다른 패러다임의 DB를 사용할 수도 있겠지만 스케일 아웃과 유연성으로 인한 이점을 얻기 위해서 consistency 같은 기존 원칙을 무너뜨리고도 자유로움을 허용하는 패러다임이 부상할 수 있다는 걸 알게 되었다.
결국 기술은 trade off라는 말은 변하지 않는 진리인 것 같다. 마찬가지로 silver bullet이 없다는 것처럼 말이다.
아래 링크에서 많은 도움을 받았습니다.
감사합니다.
https://velog.io/@songa29/AWS-DynamoDB%EB%9E%80
https://yoo11052.tistory.com/174
https://www.youtube.com/watch?v=1nE609C6-SI
https://www.youtube.com/watch?v=t_8NmwAy4D0
https://www.youtube.com/watch?v=I7zcRxHbo98
https://www.youtube.com/watch?v=IxjbhXVi1ZM
https://www.youtube.com/watch?v=c58SsQ70QQ8
https://docs.aws.amazon.com/amazondynamodb/latest/developerguide/Introduction.html
https://www.youtube.com/watch?v=5llIti9VK48
https://velog.io/@hanseul/AWS-DynamoDB-%EC%82%AC%EC%9A%A9%EA%B8%B0
https://changhoi.kim/posts/database/dynamodb-internals-1/
https://changhoi.kim/posts/database/dynamodb-internals-2/
'Cloud > AWS' 카테고리의 다른 글
| [AWS] DynamoDB에서 쓰기 충돌을 방지하는 방법 (0) | 2023.11.10 |
|---|---|
| [AWS] AWS EBS에 대한 이해 (0) | 2023.10.27 |
| [AWS] EC2를 사용하지 않을 경우 Elastic Ip / 탄력적 ip에서 과금 발생 (0) | 2022.04.08 |
| [AWS] AWS ec2 putty 연결 (0) | 2022.03.18 |
| [AWS] ssh를 사용해서 AWS EC2 접속 시 주의사항 (0) | 2021.09.11 |