교육 프로그램에 참가한지 2일차가 되었다.
1일차에 전반적인 개요와 방법에 대해 설명해보았다면 2일차에는 실제로 어떻게 진행되는지에 대해 알아보았다.
1일차와는 달리 어려움은 없었다. 그리고 실제로 어떻게 인식을 가능하게 하는지에 대해 알 수 있었다.
방법을 요약하면 간단하다.
우선 darknet이 있어야 한다. (깃허브에서 다운받으면 된다. yolo darknet을 치면 알렉세이라는 분의 깃허브가 바로 뜬다. )
그리고 이미지에서 박스 치기 즉 라벨링을 하기 위한 마킹 툴이 있어야 하는데, Yolo_mark를 사용했다. (이 툴도 알렉세이라는 분의 깃허브에서 다운 받을 수 있다. 실행방법은 해당 디렉토리로 이동한 후에 linux_mark.sh파일을 실행시키면 된다. )
해당 툴을 사용하여 (리눅스에서 사용했다.) 이미지에 라벨링을 하게 되면 txt파일이 자동으로 생성되는데, 해당 파일에는 박스의 왼쪽상단 모서리의 x,y좌표와 오른쪽 하단의 x,y좌표가 기록된다. (즉 시작점과 끝점을 의미한다.)
그렇게 가지고있었던 모든 이미지들에 라벨링을 진행하게 되면 jpg파일과 txt파일이 짝지어지게 될 것인데, 이게 바로 학습할 데이터이다. 이 데이터를 가지고 학습을 시키면 인식이 가능해지는 것이다.
(cfg파일, obj.names, obj.data등의 파일을 수정해주는 디테일한 부분도 있는데 구글링하면 더 자세한 정보를 얻을 수 있다. )
실제로 웹캠에서 인식하는것을 실습해보았는데 생각보다 잘 인식해서 신기했다.
아직 기반이론을 제대로 알지 못해서 어떻게 인식을 하는 것이고, 그 디테일한 과정이 어떻게 이루어지는지에 대해서는 감을 잡지 못했다. 하지만 툴을 활용해서, 혹은 간단한 코드를 사용해서 진행되는 과정은 알게 되었다. 그래서 밑바닥에서 어떻게 구현되고 돌아가는지에 대한 궁금증이 생겼다. 2일차는 굉장히 재밌는 과정이었고 3일차에는 직접 데이터셋을 구성해서 각 팀에서 정한 주제를 가지고 인식을 할 수 있는지를 테스트해보는 것으로 알고 있는데 그것도 재밌을 것 같다.
참고로 학습을 돌릴 떄 colab에서 어떤 GPU를 할당받았는지에 따라서 실행속도가 현저하게 차이가 난다고 한다. 보통 P-100, T-100을 받는 것이 가장 좋다고 한다. 사실 나는 이 사실을 알기 전에 T-4를 받은 상태에서 학습을 돌렸었는데, 그래서인지 상당히 오랜 시간이 걸렸다. (중간에 노트북이 저절로 잠들어서 세션이 끊기기도 했다. 영상을 틀어놓던 슬립모드를 꺼놓던 해서 학습이 중단되지 않도록 해야겠다. 물론 중간에 학습이 중단되면 가장 최근에 저장된 weight파일을 기준으로 계속 진행하면 되지만 안끊기고 계속 진행하는 것이 가장 좋다고 생각한다. 나의 경우 중간에 끊긴 상태에서 다시 실행했을 때 중간 수치에서 weight파일이 생성되지 않았다. 1000단위로 생성되어야할 weight파일이 1000,2000 그리고 6000으로 중간 부분을 건너뛰었다. 나만 그런지 모르겠지만 이왕이면 한번에 끝내는 게 낫다. )
그래서 항상 colab에서 학습을 돌릴때는 GPU로 런타임유형이 잡혀있는지 확인하고 !nvidia-smi를 통해 할당받은 GPU가 어떤 것인지 확인하고 너무 성능이 낮은 것이 할당되면 세션을 끊고 다시 할당받는 것이 좋다.
또한 조장을 하게 되었는데 팀원분들이랑 소통이 너무 잘되서 감사함을 느꼈다. 다양한 의견을 내주시고 부족한 부분 혹은 빈약한 아이디어에 대해서는 합리적인 이유를 들어 제외하는 방법을 통해 꽤나 괜찮은 주제를 선정하게 되었다. 난이도와 데이터를 쉽게 구할 수 있는지의 여부 등 여러가지 이유를 종합하여 주제를 선정하게 되었다. 우리조의 주제는 인종을 구별해내는 것이다. 한 사람당 하나의 클래스를 맡아서 데이터셋을 만들게 될텐데 그럴 경우 딱 세명에게 한가지클래스가 할당될 수 있다는 점에서도 괜찮은 주제라고 생각되어 선정하게 되었다. 황인, 백인, 흑인 순으로 각각 데이터를 모아 학습데이터를 형성하면 될 것 같다.
이후에는 꼭 정면이 아니더라도 옆모습, 비스듬한 모습에서도 인식할 수 있도록 개선하는 방법으로 나아가면 좋은 결과가 나올 것이라 생각한다.
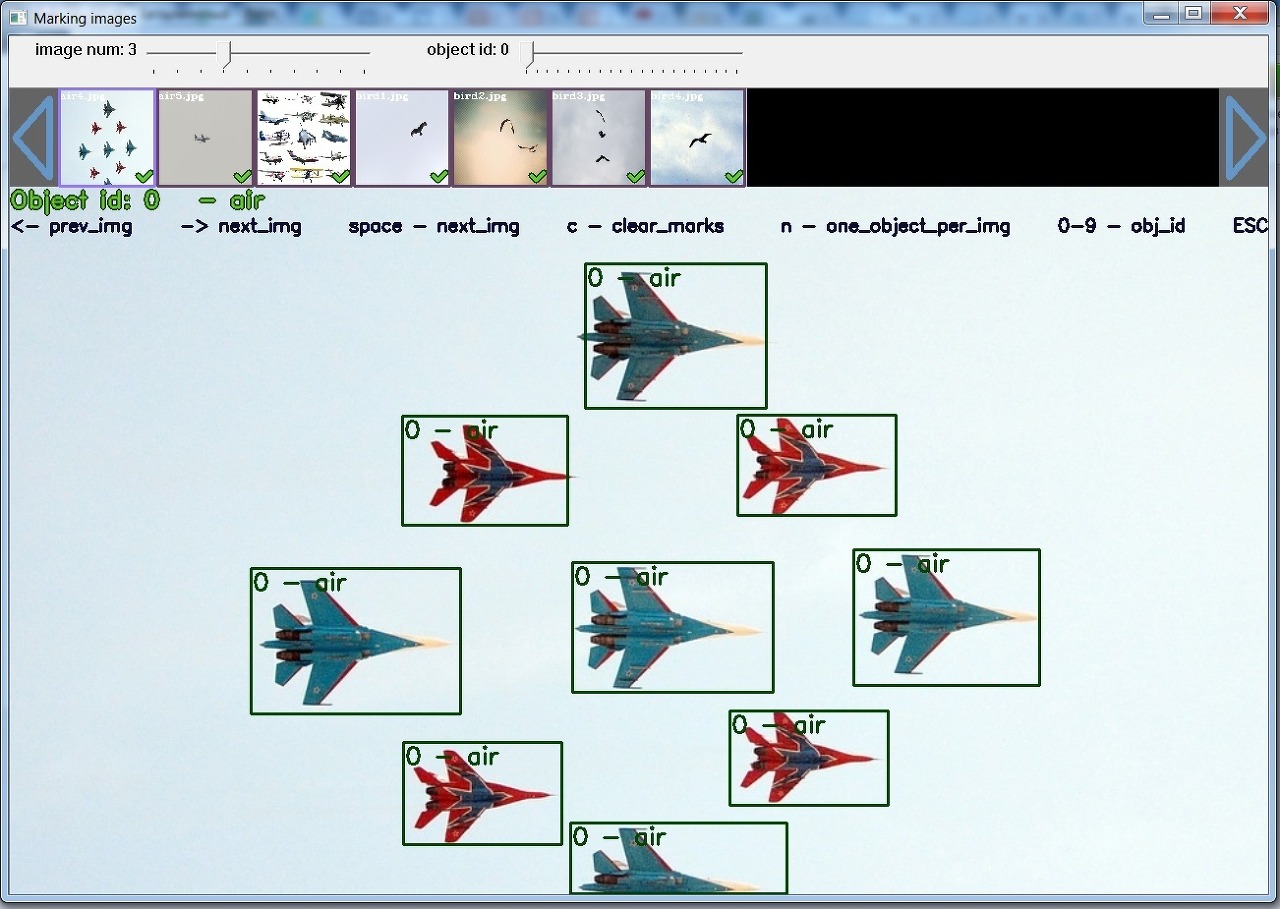
아래 깃허브에서 Yolo_mark를 다운받을 수 있다.
https://github.com/AlexeyAB/Yolo_mark
GitHub - AlexeyAB/Yolo_mark: GUI for marking bounded boxes of objects in images for training neural network Yolo v3 and v2
GUI for marking bounded boxes of objects in images for training neural network Yolo v3 and v2 - GitHub - AlexeyAB/Yolo_mark: GUI for marking bounded boxes of objects in images for training neural n...
github.com
'AI > 2021 AI엔지니어 고급반' 카테고리의 다른 글
| 2021AI엔지니어 고급반 - YOLO with deep learning 교육 프로그램 참가 후기 5일차 (0) | 2021.08.27 |
|---|---|
| 2021AI엔지니어 고급반 - YOLO with deep learning 교육 프로그램 참가 후기 4일차 (0) | 2021.08.26 |
| 2021AI엔지니어 고급반 - YOLO with deep learning 교육 프로그램 참가 후기 중간 결과물 (0) | 2021.08.25 |
| 2021AI엔지니어 고급반 - YOLO with deep learning 교육 프로그램 참가 후기 3일차 (0) | 2021.08.25 |
| 2021AI엔지니어 고급반 - YOLO with deep learning 교육 프로그램 참가 후기 1일차 (0) | 2021.08.23 |